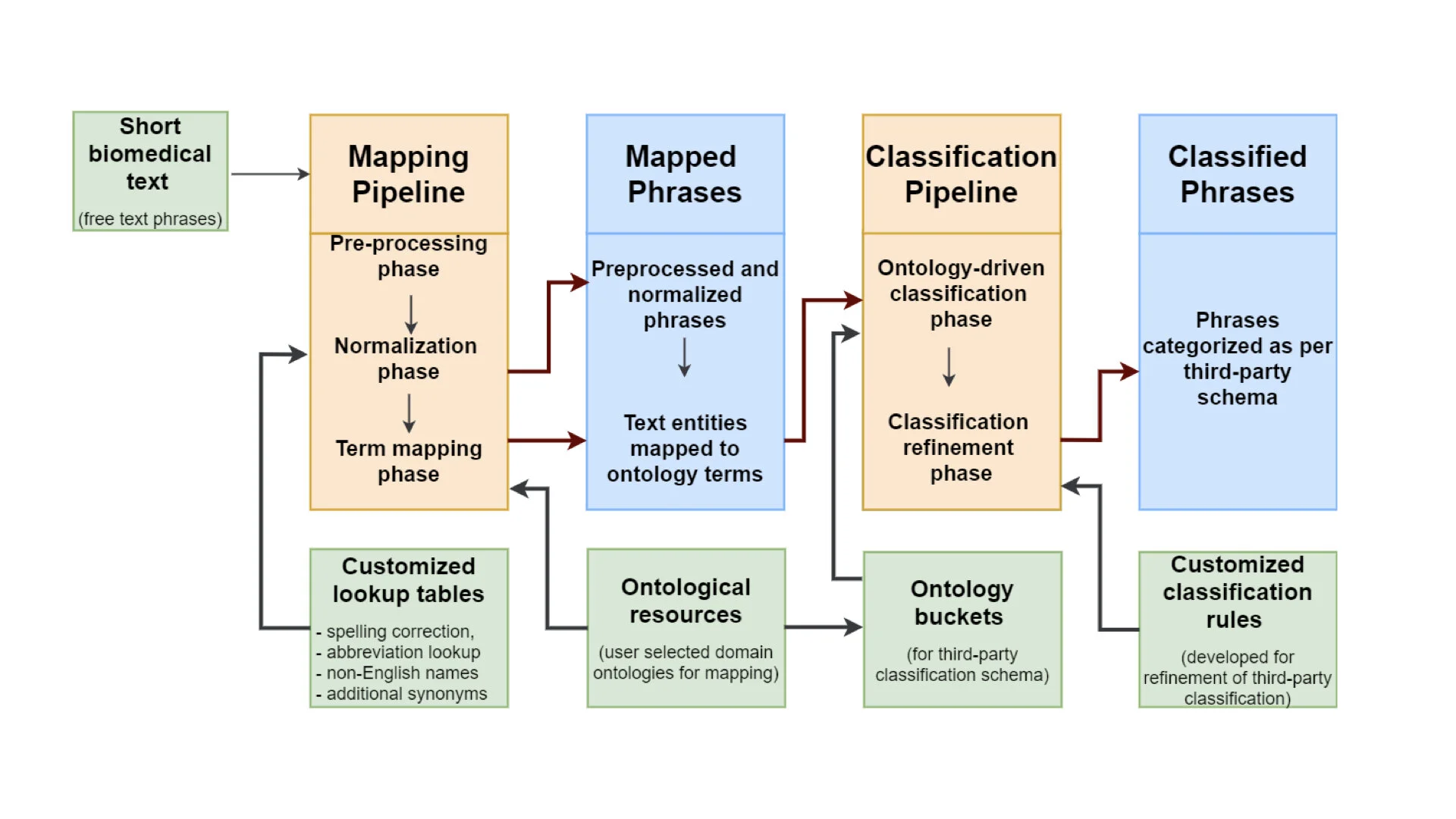
This month’s blog was written by Nicola Mulder, Professor and head of the Computational Biology division at the University of Cape Town, and Principal investigator of H3ABioNet, a Pan African bioinformatics network for H3Africa, and Mamana Mbiyavanga, a Bioinformatics Scientist and PhD student at UCT, who contribute to a diverse range of CINECA work packages. This blog is less of a technical report in our Global Alliance for Genomics and Health (GA4GH) standards series than the previous 4, and more of a report on how WP6 - ‘Outreach, training and dissemination’ is contributing to developing better implementation of GA4GH standards.
Read More