The video is aimed at presenting what is the Query Expansion (QE) and introducing all the QE services developed by WP1.
Read MoreThe video is aimed at presenting what is the Query Expansion (QE) and introducing all the QE services developed by WP1.
Read MoreThe video is aimed at presenting what is Horizontal Expansion, a QE service that retrieves synonyms based on semantic similarities.
Read MoreThe video is aimed at presenting what is the Vertical Expansion, a QE service that retrieves hypernyms and hyponyms aka the parents and the children of a concept in a specific ontology.
Read MoreThis month’s blog was written by Melanie Courtot, metadata standards coordinator at EMBL-EBI and co-Work Package Lead of CINECA WP3 - Cohort Level Metadata Representation. This blog is the fourth in our Global Alliance for Genomics and Health (GA4GH) standards series, presenting an overview of how GA4GH standards are being developed and implemented by CINECA. In our April post about Passport, Mikael from CINECA WP2 explained the importance of controlled-access to protect sensitive data, federated data access in the cloud and how Passport enables researchers to authenticate - prove they are who they say they are.
Read MoreThis post is part of a series on a text-mining pipeline being developed by CINECA in Work Package 3. In previous instalments, first, Zooma and Curami pipelines were explained in "Uncovering metadata from semi-structured cohort data". Then, LexMapr was introduced in "LexMapr - A rule-based text-mining tool for ontology term mapping and classification". In this third instalment we are going to explain the normalisation pipeline developed at SIB/HES-SO.
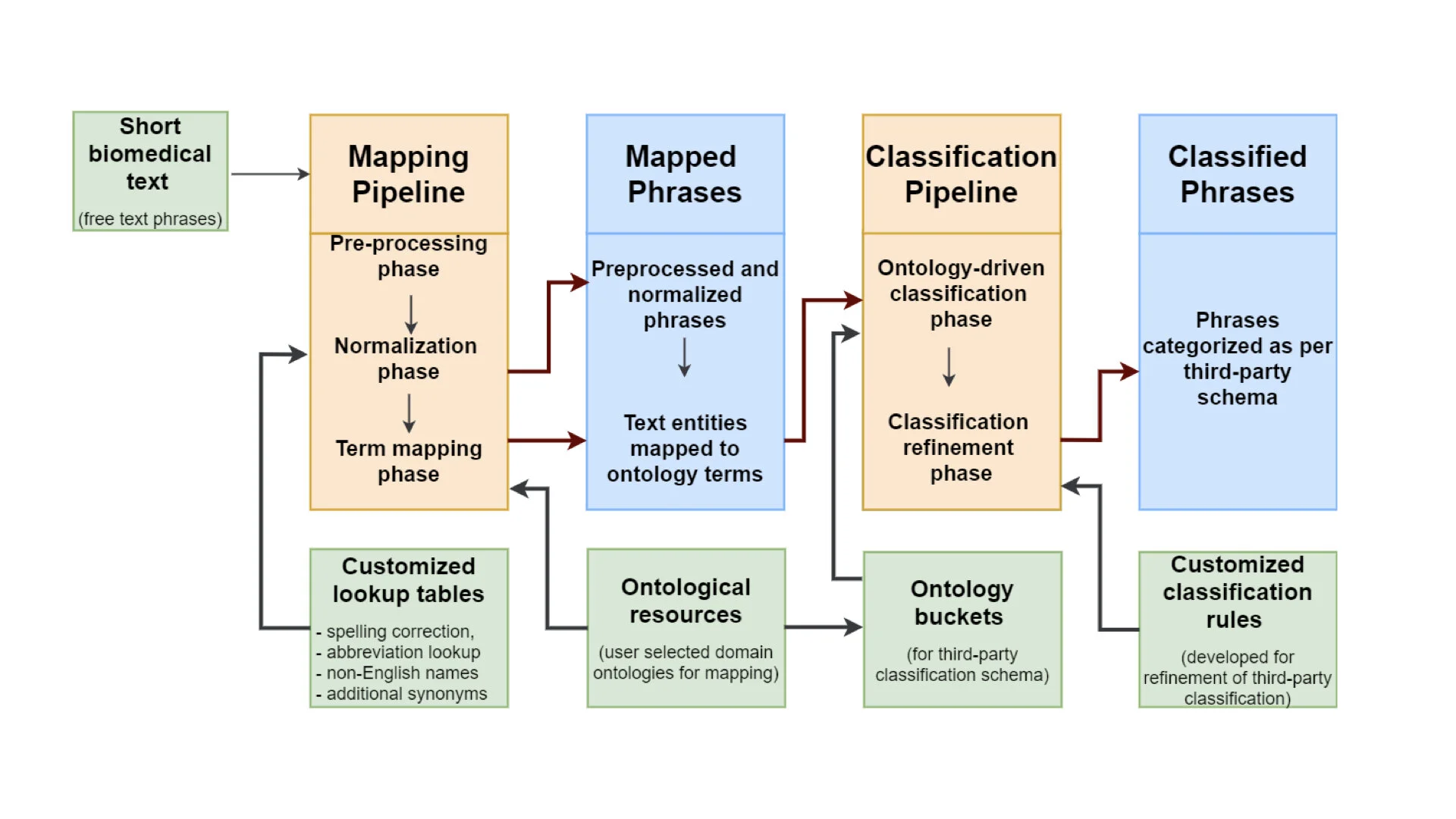
Read MoreThe initial focus of LexMapr development has been on providing a text-mining tool to clean up the short free-text biosample metadata that contained inconsistent punctuation, abbreviations and typos, and to map the identified entities to standard terms from ontologies. This blog is the second in a series on text-mining in CINECA. For the previous instalment "Uncovering metadata from semi-structured cohort data" please click here.
Read MoreHarmonisation of attributes across different cohorts is very challenging and labour intensive, but critical to leverage the collective potential of the data. The CINECA text mining group aims to provide common tools and methods to extract additional metadata from structured and semi-structured fields in cohorts’ data.
Read More