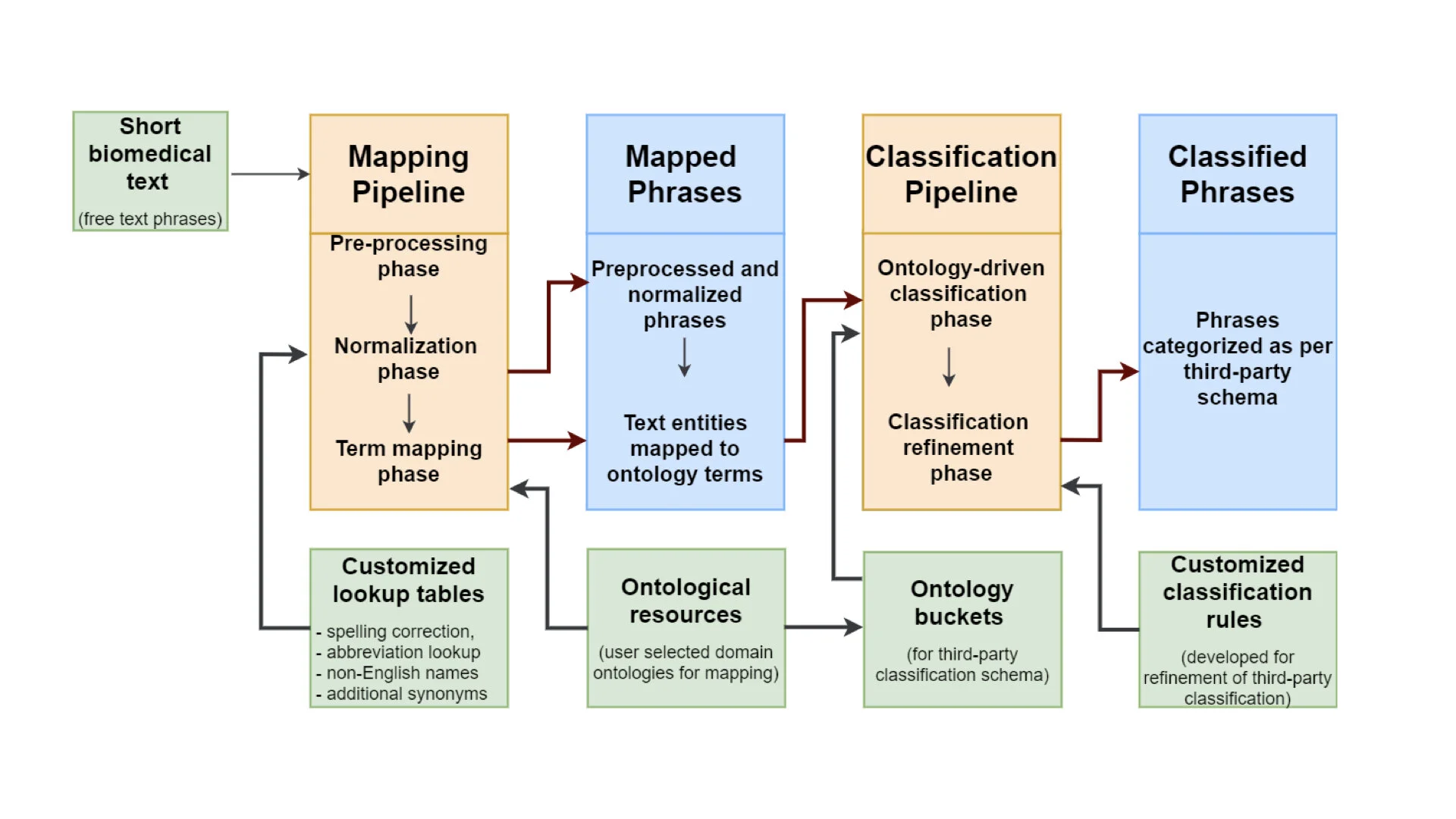
This post is part of a series on a text-mining pipeline being developed by CINECA in Work Package 3. In previous instalments, first, Zooma and Curami pipelines were explained in "Uncovering metadata from semi-structured cohort data". Then, LexMapr was introduced in "LexMapr - A rule-based text-mining tool for ontology term mapping and classification". In this third instalment we are going to explain the normalisation pipeline developed at SIB/HES-SO.
Read More