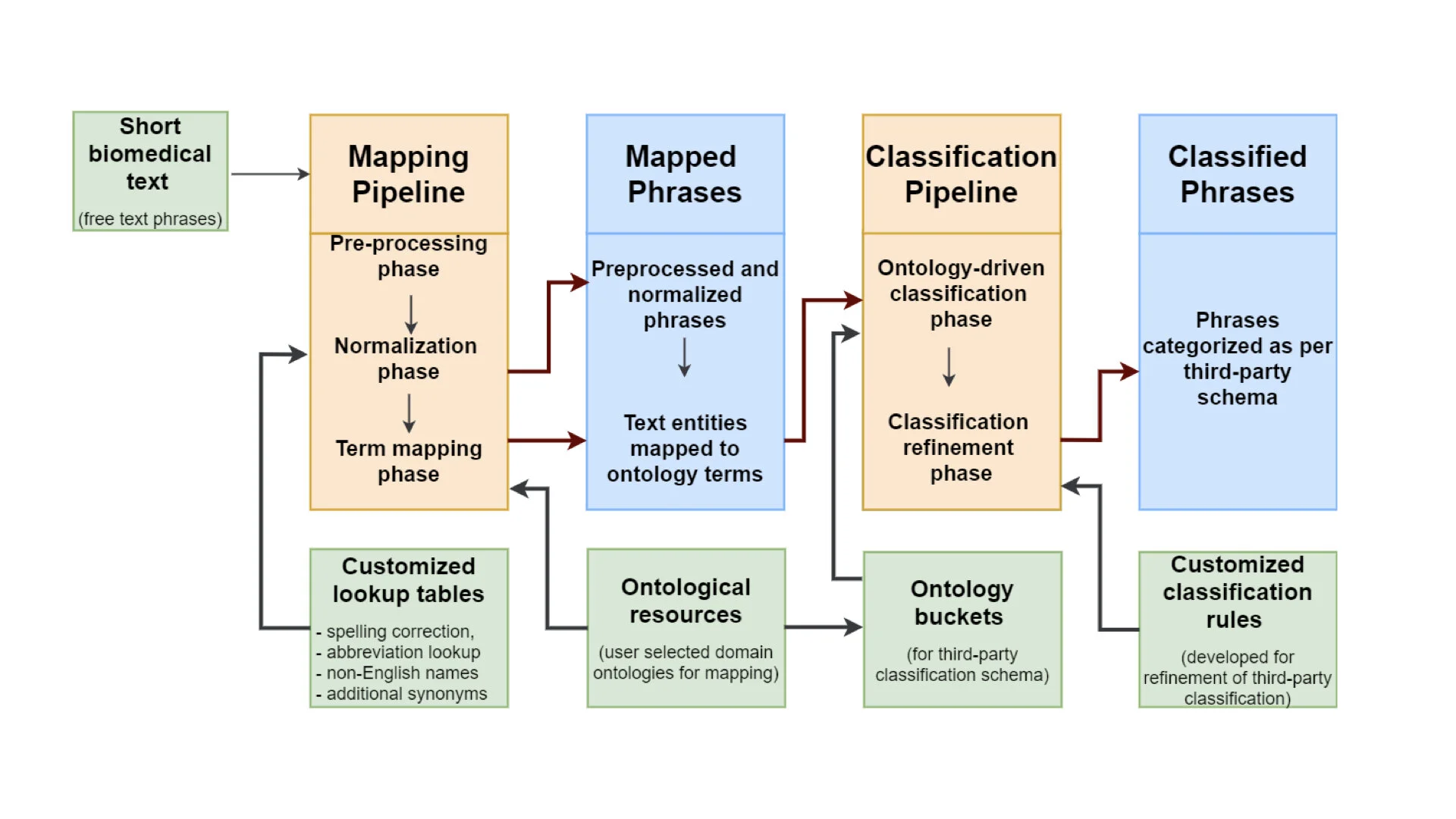
This video describes how public health genomics has played a key role in international responses to the COVID-19 pandemic, and how data standards are being used to harmonize data across jurisdictions for Canadian COVID-19 surveillance and outbreak investigations. The video is aimed at anyone interested in data standardization and/or the ontology approach (i.e. public, end users). No prerequisite knowledge is required, but viewers may also find our previous videos useful. This video is part of the CINECA online training series, where you can learn about concepts and tools relevant to federated analysis of cohort data.
Read More