Willem de Koning, Milad Miladi, Saskia Hiltemann, Astrid Heikema, John P Hays, Stephan Flemming, Marius van den Beek, Dana A Mustafa, Rolf Backofen, Björn Grüning, Andrew P Stubbs
In this paper, de Koning, et al describe “NanoGalaxy", a Galaxy-based toolkit for analysing long-read sequencing data, suitable for diverse applications, including de novo genome assembly from genomic, metagenomic, and plasmid sequence reads.Read the full publication here.
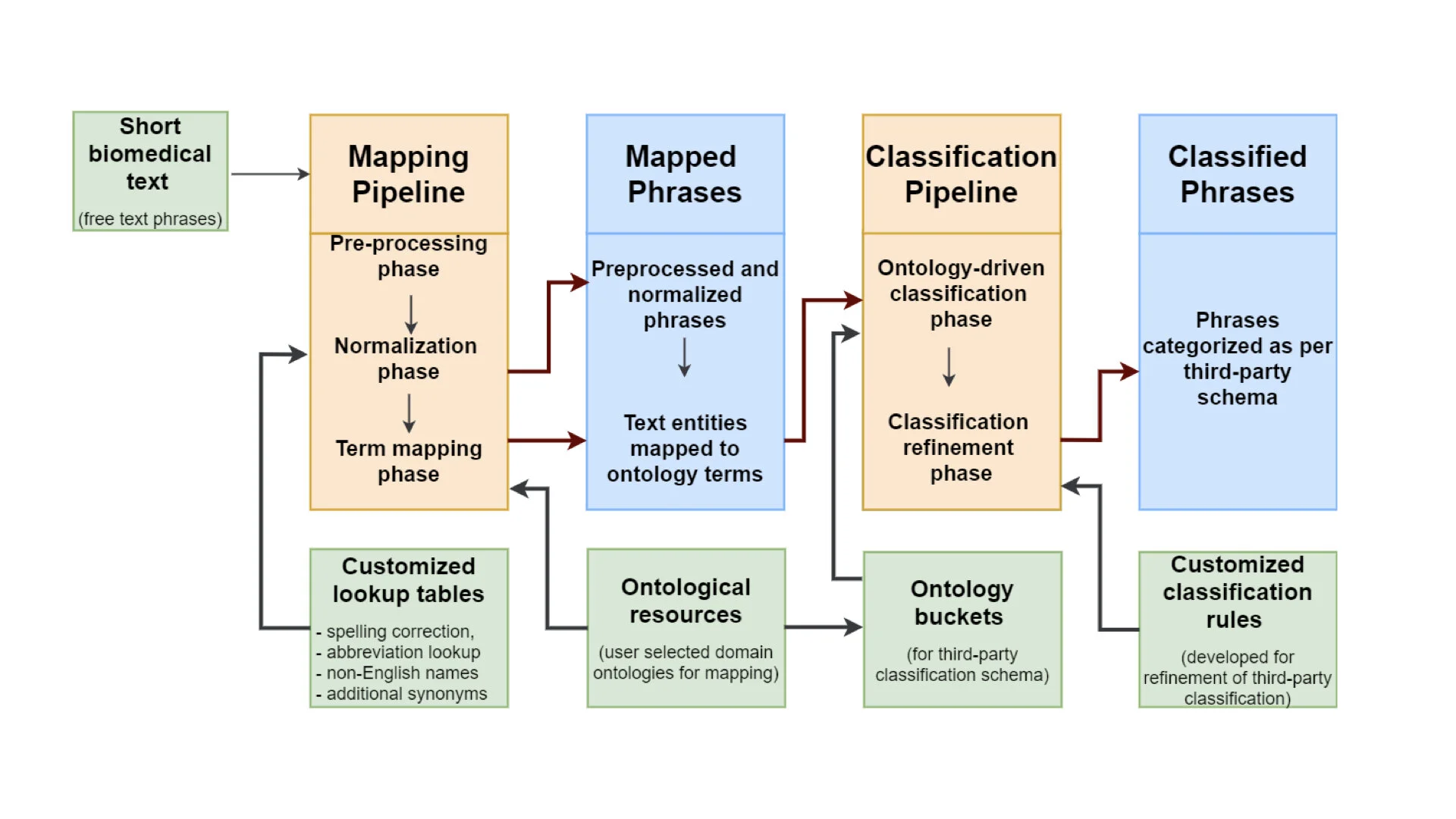
The initial focus of LexMapr development has been on providing a text-mining tool to clean up the short free-text biosample metadata that contained inconsistent punctuation, abbreviations and typos, and to map the identified entities to standard terms from ontologies. This blog is the second in a series on text-mining in CINECA. For the previous instalment "Uncovering metadata from semi-structured cohort data" please click here.
This video demonstrates how a service registry can operate with additional functionality when integrated more closely with the services providing queries (here, Beacon queries).
This video demonstrates how a standalone service registry operates, and our extensions to the service info and service registry standards to include cohort-level metadata.